Usecase: data z webu bezrealitky.cz
Webscraping umožňuje získat data z webu, který obsahuje data, ale není a třeba ani nechce být uzpůsobený k jejich souhrnému poskytování. Mně jako jeden z možných příkladů napadají realitní weby. Je jedno který, ale je mi například sympatický web bezrealitky.cz
Pythoní skript který jsem použil je dostupný na mém Githubu. Nutno podotknout, že dost pravděpodobně nebude moc dlouho funkční, protože se takovéto weby poměrně často mění, takže kdybyste ho chtěli použít a nešlo vám to, bude potřeba něco málo opravit.
Když už jsem data vydoloval pomocí Pythonu, tak je můžu pomocí Pythonu i analyzovat. Zde jsem používal Pandas, NumPy, Matplotlib Pyplot, Seaborn a Stats od SciPy. Tento webscrape zas tak mnoho parametrů nezískal, ale i tak je to zajímavý pohled. Postup analýzy lze nalézt zde.
V první řadě je vždy dobré podívat se na outliery. Mně se u získaných dat pořád nezdálo, co to tam vidím za šílenou částku zrovna u nějakého 1+kk v Libni.
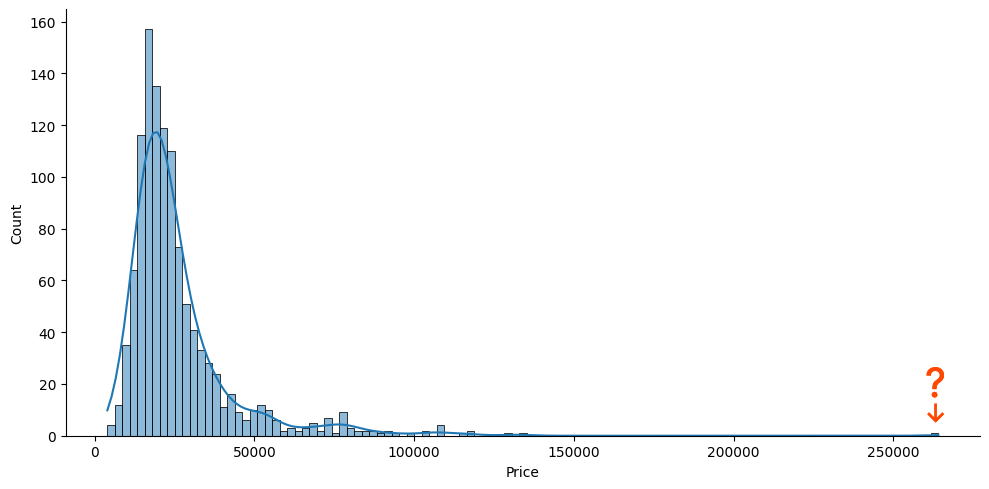
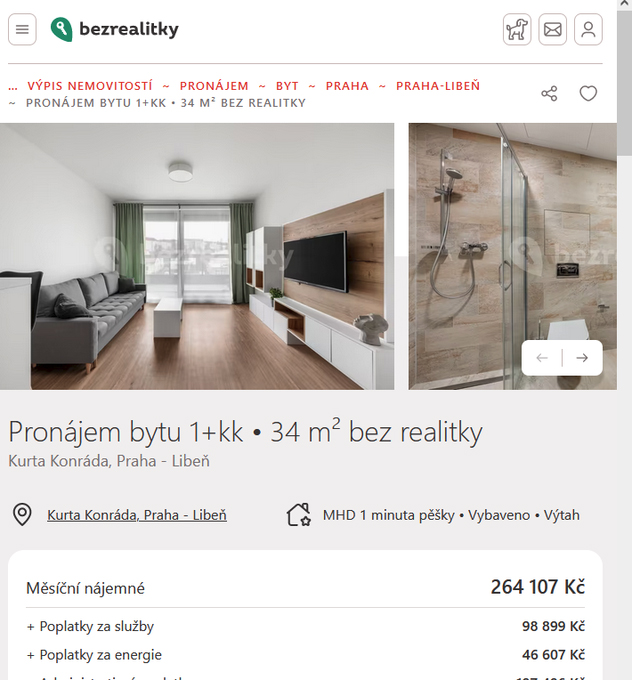
Nicméně ukázalo se, že tento inzerát skutečně v danou chvíli existuje, a nezbývá než se jej raši zbavit coby outliera. Jak se stalo, že někdo něco tak malého nabízí v této lokalitě za tyto peníze? Těžko říct, ale rozhodně chyba není na mém příjimači.
Podobně i podlahová plocha obsahuje nějaké outliery, a to jak jakýsi gigantický podkrovní loft, tak opět jakýsi renonc, který má evidentně 30 a nikoli 300 m².
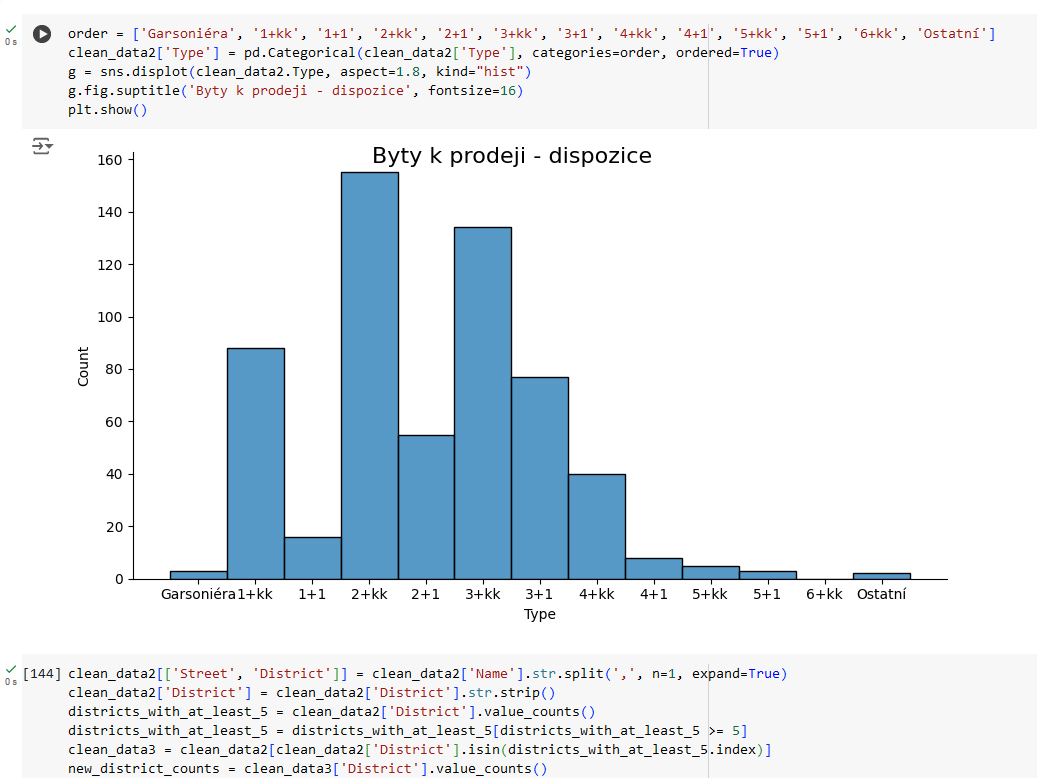
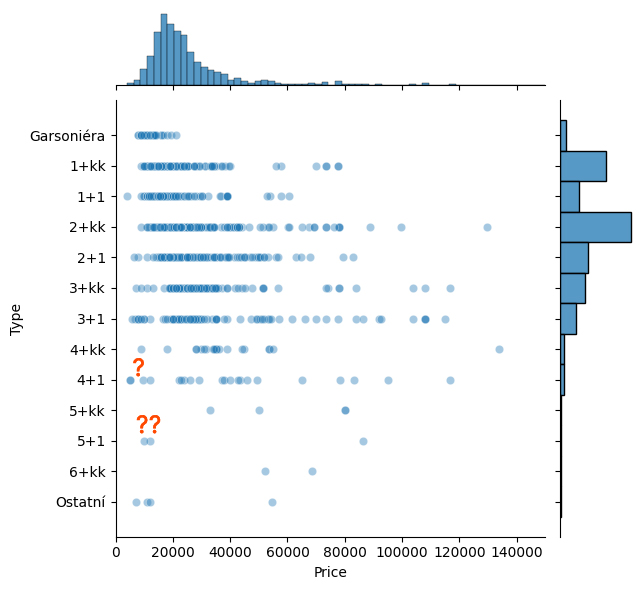
Pokud se nahrubo podíváme na to, jak moc dispozice bytů odpovídají cenám, vidíme další nesmysly, tentokrát byty o dispozici 4+1 nebo 5+1, u kterých je špatné uvedená dispozice, nebo se ve skutečnosti jedná o pronájem pokoje v takto velkém byt. Data jsou tedy zaplevelená jednotlivými nesmysly a pro skutečně důkladnou analýzu je dobré je identifikovat a eliminovat.
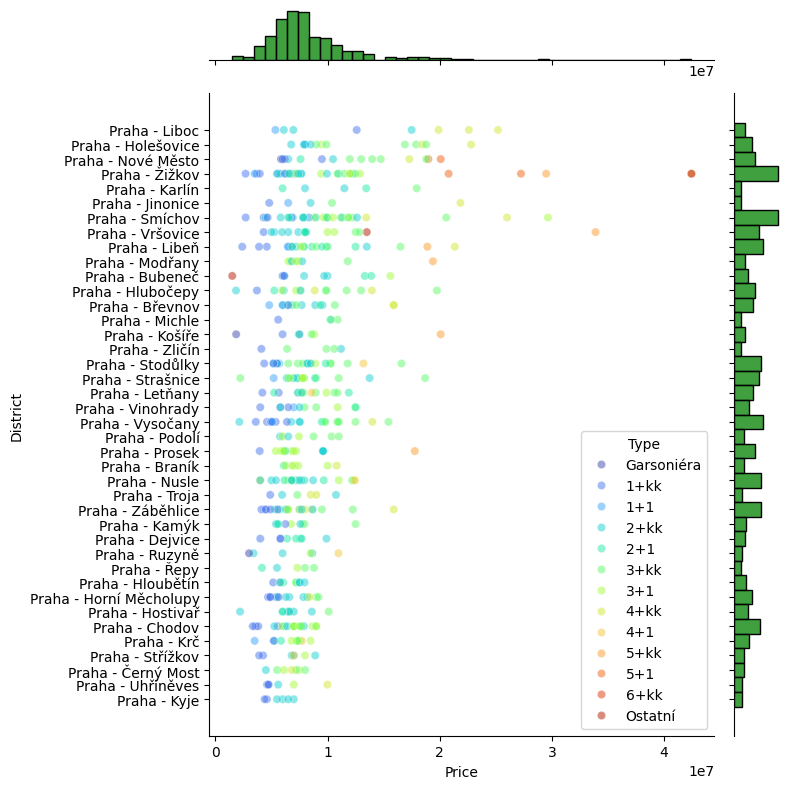
Po očištění se můžeme bez obav o práci se zkreslenými daty dál zabývat tím, co lze z dat vyčíst, třeba jak si na tom ve srovnání stojí jednotlivé pražské čtvrti, ať už z hlediska průměrné ceny (vlevo), tak rozložení cen (vpravo):
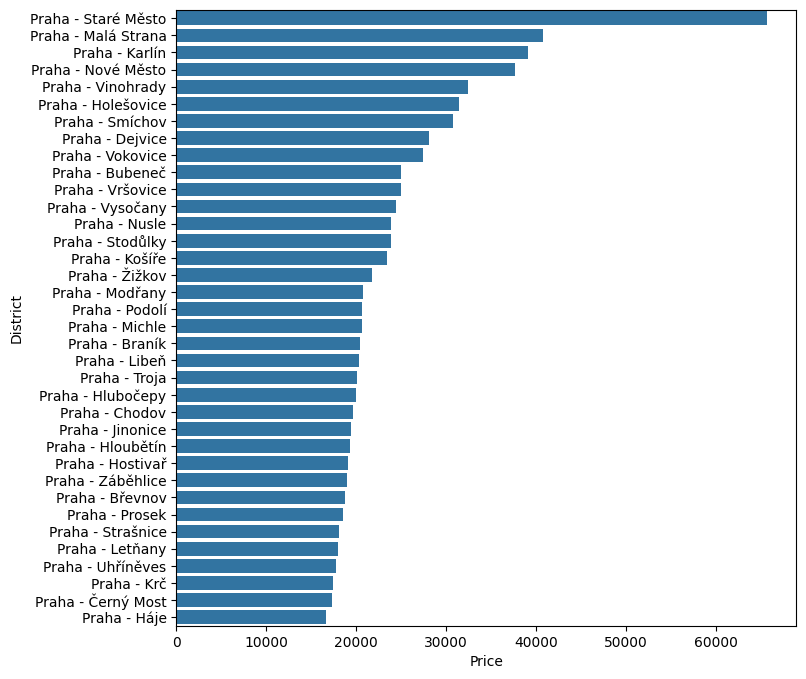
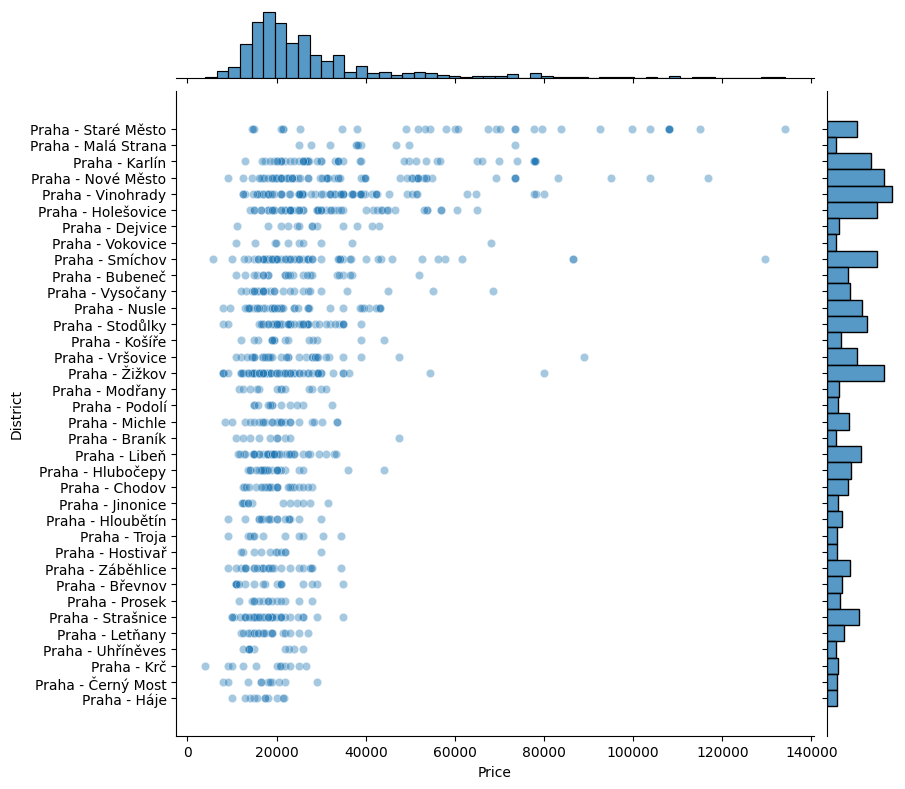
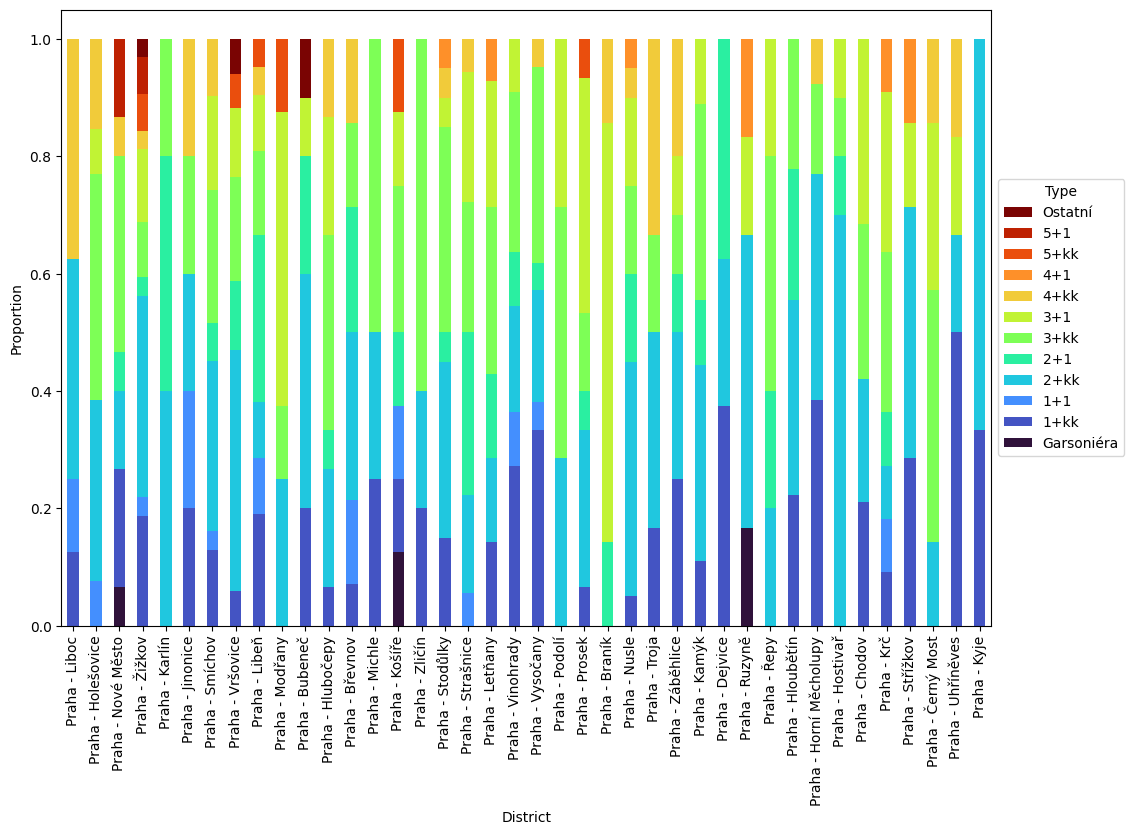
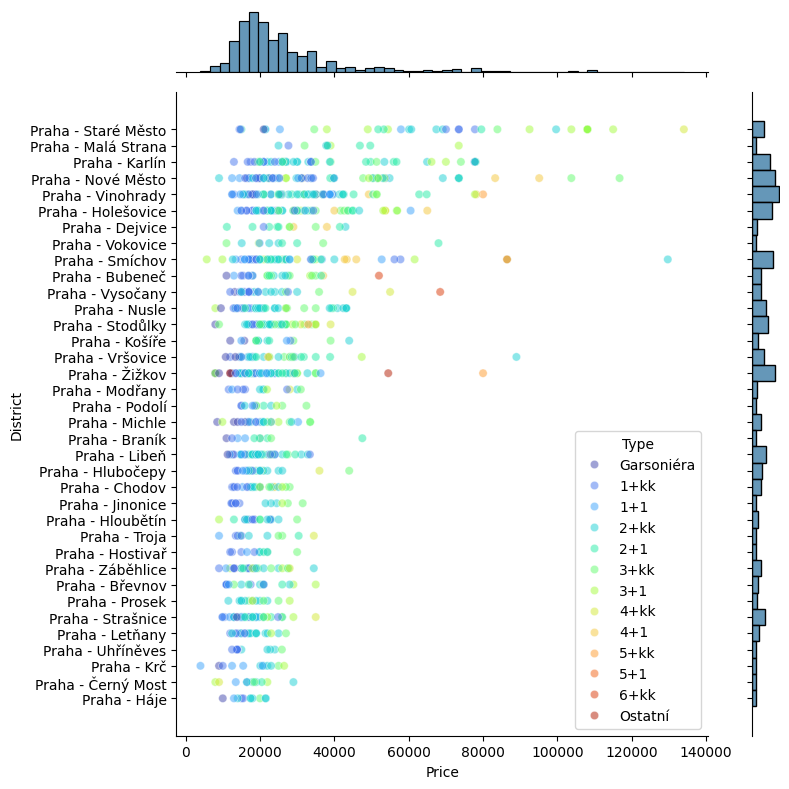
Na základě všech dostupných proměnných pak lze z dat tahat doslova turbobarevné (palette='turbo') grafy, které zobrazují informaci o dispozicích, lokaci i ceně, a to jak ve formě rozložení (vlevo), tak zastoupení dispozic v jednotlivých čtvrtích (vpravo):

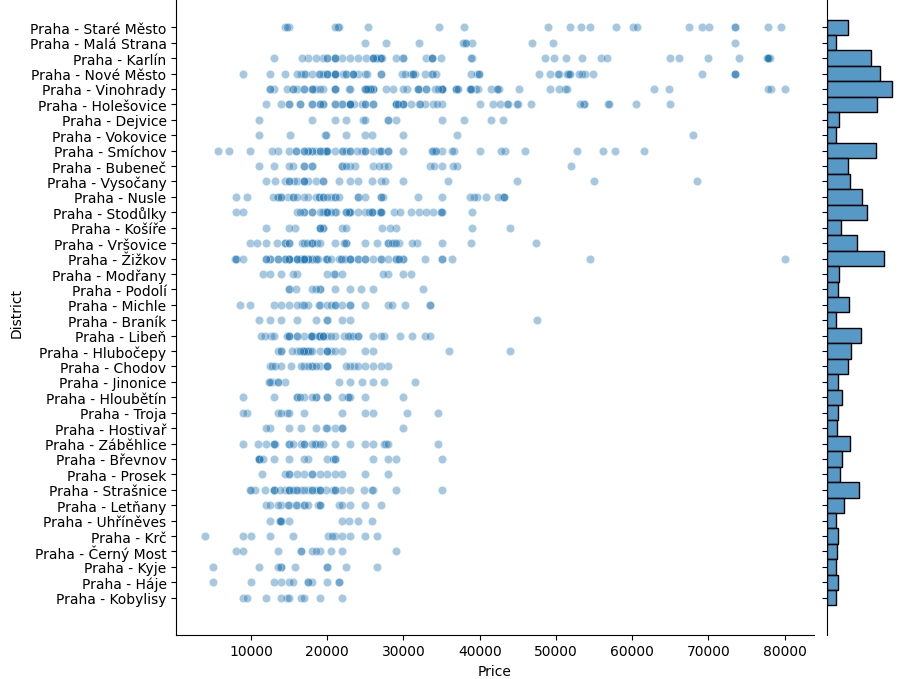
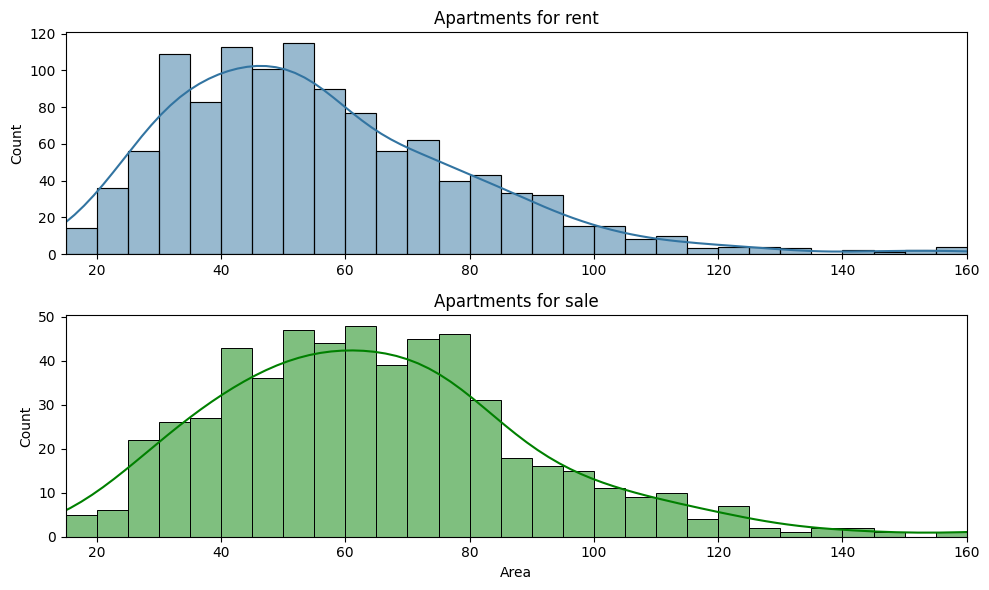
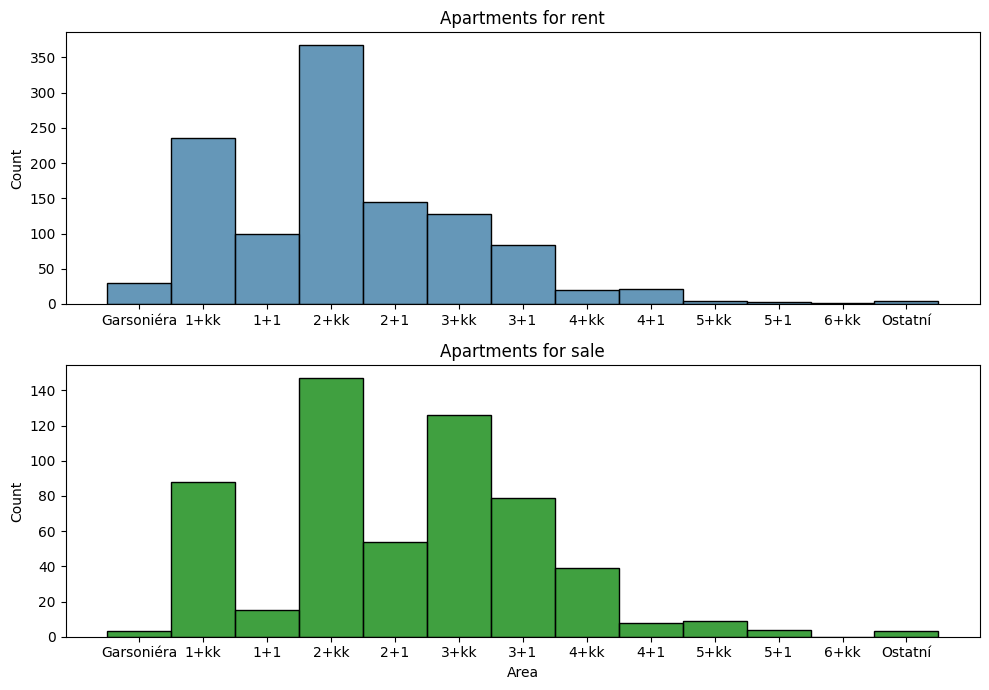
Stejným způsobem je samozřejmě možné vyscrapeovat data týkající se bytů na prodej. Samozřejmě, že počet položek je zde jiný (v tomto případě téměř o polovinu), ale to nám nebrání vytvořit určité srovnání. Kupříkladu podlahová plocha bytů k pronájmu se pohybuje viditelně v jiných relacích:
Stejná informace zobrazená jiným způsobem nám pak ukáže, že rozdíl v zastoupení v nabídce je především v dispozicích 1+1 a 3+kk:
Pokud se pohrabeme v datech z hlediska prazškých čtvrtí, vidíme zde zcela jiný obrázek než u nabídky pronájmů. "Vítězem" se stává Liboc, při bližším ohledání však zjišťujeme, že tato data značně deformuje nabídka pěti bytů v jakési novostavbě Rezidence Liboc. Vzhledem k tomu, že se jedná o malou čtvrť, většinu jejíž rozlohy zabírají Divoká Šárka a obora Hvězda, dochází zde tedy svým způsobem k velké chybě malých čísel.
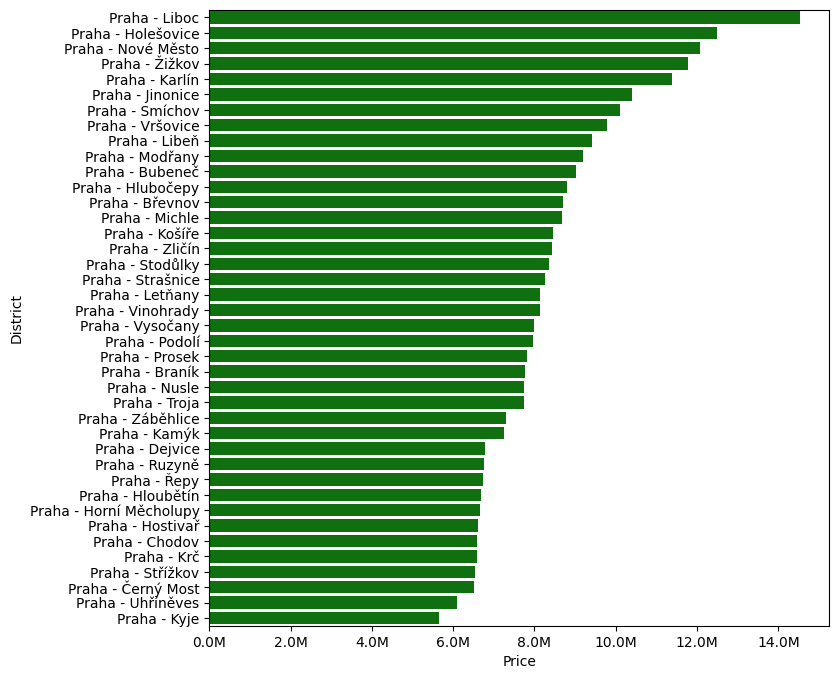
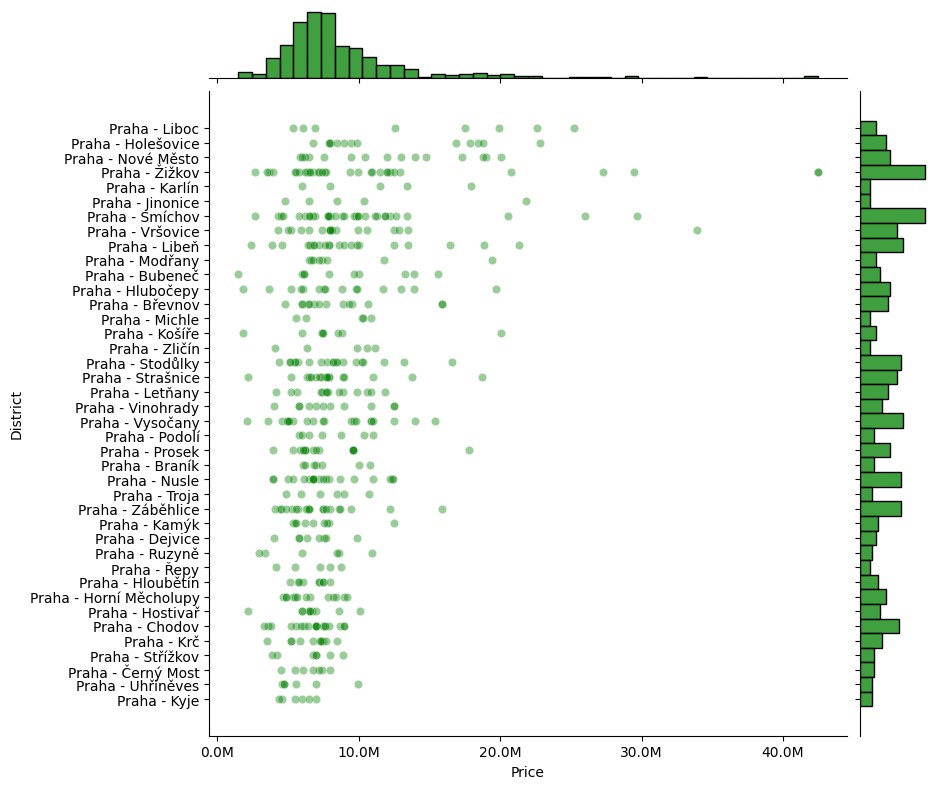
Na druhé straně cenové nabídky jsou jednoznačným vítězem Kyje. I zde je poměrně jednoduché najít vysvětlení. Pokud aplikujeme stejný postup na analýzu nabídky dispozic, jako u nabídky pronájmů, vidíme na první pohled, že v den, kdy jsme scrapeovali data, byly v Kyjích k nabídce jen malé byty: